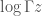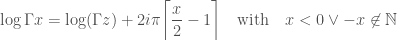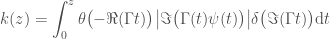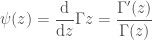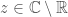It’s been a bit since I started the series and, freely admitted, forgot to add the last part, the actual implementation of Peter B. Borwein’s algorithm[1] for computing factorials.
Some changes from the past: the language changed from Javascript to the script language implemented in Calc. It is easier to read and can be used as runnable pseudo-code. And it is a bit faster than my Javascript implementation of a big-integer library.
A short summary of the algorithm goes:
- Factorize the factorial
- Exponentiate the primes according to the factorization
- Compute the product of the above powers
To factorize a factorial no factorization of the fully computed factorial is needed. Obviously. The number theoretical background is given at Wikipedia, at Wolfram`s and elsewhere, too.
There are several methods to do that but simple trial division is good enough; these are small numbers: the largest possible exponent is the exponent of the smaller prime, that would be 2 and since 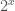 cannot exceed
cannot exceed 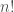 if is a prime factor so
if is a prime factor so  cannot exceed
cannot exceed  . Proof omitted, ask Adrien-Marie Legendre if you need one.
. Proof omitted, ask Adrien-Marie Legendre if you need one.
The time complexity to do the computation is O(log n) or, in this case, exactly 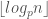 integer divisions with
integer divisions with 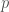 prime the base of the logarithm, therefore only half of the primes have exponents
prime the base of the logarithm, therefore only half of the primes have exponents  . We might treat these separately.
. We might treat these separately.
/* A simple list to keep things...uhm...simple?*/
global __CZ__primelist = list();
/* Helper for factorial/primorial: fill list with primes in range a,b */
define __CZ__fill_prime_list(a,b)
{
local k;
k=a;
/*
nextprime(k) means next prime even if k is prime. This is
different from the behaviour of other programs e.g.; PARI/GP
*/
if(isprime(k))k--;
while(1){
k = nextprime(k);
if(k > b) break;
append(__CZ__primelist,k );
}
}
/* Helper for factorial: how often prime p divides the factorial of n */
define __CZ__prime_divisors(n,p)
{
local q,m;
q = n;
m = 0;
if (p > n) return 0;
if (p > n/2) return 1;
while (q >= p) {
q = q//p; /* double forward slash is integer division */
m += q;
}
return m;
}
To make it more complete and easier to follow we get the primes from a generated list, you might use your own implementation of a sieve or similar methods to get the primes.
Now that we have that ready we can go on, power up, and exponentiate the primes according to the results from above.
/* Helper for factorial: exponentiate p^k */
define __CZ__exponentiate(prime,exponent) {
local bit result temp;
result = 1;
bit = digits(exponent,2);
/* strip leading zeros */
while((exponent & (1 << bit)) == 0) bit--;
for( ; bit>=0 ; bit--){
result = result^2;
/* square if bit is zero, multiply otherwise */
if((exponent & (1 << bit)) != 0){
result *= prime;
}
}
return result;
}
The method here is the so called binary exponentiation and has a bit (ha!) of optimization. A simpler and more readable piece of code is probably
define exponentiate(base,exponent)
{
local result e b;
result = 1;
b = base;
e = exponent;
while(e != 0){
if(isodd(e)){
result = result * b;
}
e = e>>1;
if(e != 0){
b = b^2;
}
}
return result;
}
This method allows for less multiplications and even better: more squaring which can be done faster than multiplication.
Apropos faster: we already have the number of times 2 divides 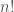 and because shifting is cheap in modern computers it is advisable to use that fact and drop
and because shifting is cheap in modern computers it is advisable to use that fact and drop 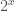 from the product and just shift by at the end. The second half of the primes have exponent 1 (one) and it is a better idea to treat the separately as a fraction of two primorials
from the product and just shift by at the end. The second half of the primes have exponent 1 (one) and it is a better idea to treat the separately as a fraction of two primorials 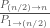 and compute the product with the help of binary splitting.
and compute the product with the help of binary splitting.
Now, lets get it all together.
local prime result prime_raised shift cut;
result = 1;
prime = 2;
/* checks and balances omitted */
shift = __CZ__prime_divisors(n,prime);
prime = 3;
cut = n//2;
do {
prime_raised = __CZ__exponentiate(prime,__CZ__prime_divisors(n,prime));
result *= prime_raised;
prime = nextprime(prime);
} while(prime <= cut);
result *= primorial( cut, n);
result <<= shift;
return result
What? Oh, sorry, the primorial, yes.
define primorial( a, b)
{
local C1;
/*
Checks and balances omitted bt keep in mind that the number of primes you
get from functions like nextprime() might be limited. Here the limit is
2^32 so the last prime you can get with nextprime() is 4294967291.
*/
__CZ__fill_prime_list(a,b);
C1 = size(__CZ__primelist)-1;
return __CZ__primorial__lowlevel( 0, C1,1)
}
The actual product gets, as promised, calculated with a simple binary splitting algorithm:
/*
Helper for primorial: do the product with binary splitting
TODO: do it without the intermediate list
*/
define __CZ__primorial__lowlevel( a, b ,p)
{
local c;
if( b == a) return p ;
if( b-a > 1){
c= (b + a) >> 1;
return __CZ__primorial__lowlevel( a , c , __CZ__primelist[a] )
* __CZ__primorial__lowlevel( c+1 , b , __CZ__primelist[b] ) ;
}
return __CZ__primelist[a] * __CZ__primelist[b];
}
As we can see it is the very same algorithm as the binary splitting algorithm for the factorial itself with the single difference that a,b are not to be multiplied themselves but act as indices to the ordered(!) list of primes.
This method would lower the time complexity of the complete algorithm if we exponentiate the primes in-place and run the above algorithm over the whole list instead of the upper half only.
We should grab the chance and make some things more general, for example the product of the list of primes can easily be the product of any ordered list. Please be carefull if is possible to persuade your language to pass arguments by pointer and not by copying the whole thingamabob every f’ing time.
define product_list( a, b ,p,list)
{
local c;
if( b == a) return p ;
if( b-a > 1){
c= (b + a) >> 1;
return product_list( a , c , list[a],list )
* product_list( c+1 , b , list[b],list ) ;
}
return list[a] * list[b];
}
It is also possible now to skip the global variable which is in most cases a bad idea to have; only in rare cases it is a very bad idea.
define factorial2(n){
local prime result shift cut prime_list k;
result = 1;
prime = 2;
prime_list = list();
shift = __CZ__prime_divisors(n,prime);
prime = 3;
cut = n//2;
/* first half with exponentiation */
do {
append(prime_list,__CZ__exponentiate(prime,__CZ__prime_divisors(n,prime)));
prime = nextprime(prime);
} while(prime <= cut);
/* first half rare primes only */
do{
append(prime_list,prime );
prime = nextprime(prime);
}while(prime <= n);
k = size(prime_list)-1;
result = product_list( 0, k,1,prime_list);
result <<= shift;
return result;
}
One final note: the respective sizes of the factors in the multiplication is not very equal. That means that the use of the common methods for fast multiplication (e.g.: FFT) which depends on equal size of the multiplicands can be tricky. Simple padding is, uhm, simple but raises the n in M(n).
Well, a theme for a later posting, I guess 😉
UPDATE just an hour later.
Ok, I’ll do it now and here.
I admit: I withhold the essential trick that makes it faster than everything known before: nested squaring.
If you imaging the whole list of primes with their respective exponents and lay it flat, exponents down, primes up, and you’ll get the following:
| 2 |
3 |
5 |
7 |
… |
| 0 |
1 |
1 |
1 |
… |
| 1 |
0 |
1 |
0 |
… |
| … |
… |
… |
| … |
What we do now is reading it row-wise. Multiply the result with the respective prime if the bit is set, do nothing otherwise and when you come at the end of the row square the result, rinse and repeat.
Now we have only fast squaring and multiplication with very small primes which can be done in O(n) if the prime is smaller than one LIMB which has in most cases 32 bit if not 64.
define factorial3(n){
local prime result shift prime_list expo_list k k1 k2;
result = 1;
prime = 2;
prime_list = list();
expo_list = list();
/* Checks and balances omitted */
shift = __CZ__prime_divisors(n,prime);
prime = 3;
do {
append(prime_list,prime);
append(expo_list,__CZ__prime_divisors(n,prime));
prime = nextprime(prime);
}while(prime <= n);
/* size of the largest exponent in bits */
k1 = highbit(expo_list[0]);
k2 = size(prime_list)-1;
for(;k1>=0;k1--){
/*
Square the result every row.
One might skip the first time because 1^2 = 1.
*/
result *= result;
for(k=0; k<=k2; k++) {
/*
check every exponent for a set bit and
multiply the result with the respective prime
*/
if((expo_list[k] & (1 << k1)) != 0) {
result *= prime_list[k];
}
}
}
result <<= shift;
return result;
}
That was it! Really! Promised!
Well …
[1]Peter B. Borwein, On the Complexity of Calculating Factorials, Journal of Algorithms, 3, 1985