
Deep down in the sage bush. Yes, I have a new camera and it is a tad bit better.

Deep down in the sage bush. Yes, I have a new camera and it is a tad bit better.
Building a Toom-Cook 6-way multiplication, step by step. With comments but without the curses and the heavy math.
This is in large parts automatically translated from a Latex document to WordPress. Despite a lot of manual corrections I still have that vague idea that something is amiss or even wrong. At least the last listing works. Even Mozilla’s spellchecker failed!
1. Introduction
Why the hassle if Bodrati, Zanoni, Zimmerman or whoever comes to mind had already done it? It is simply a license problem. LibTomMath has a licence that is nearly indistinguishable from the construct Public Domain and hence cannot use any of the implementations. Bodrati for example puts all his works under the GPL.

Tegenaria domestica (female))
It’s officially winter now (yes, I’m late, as always) and the house spiders look for the warm and cozy and slightly humid places. The toilet might have been a good idea at first sight but it is not heated very well, just so much that the pipes don’t freeze. Yes, all pipes, thank you.
Sooo, this little girl (bit unsure, have not seen the underbelly but the lack of swollennes in the pedipalps hints in the direction of female) dropped herself into the little sink aside of the larger one and let me have a chance to do my good deed of the day and help her out of her misery. There you can see her waving good-bye before entering the underworld of the 70’s-green basin with all of that inviting nooks and crannies.

Argiope bruennichi (wasp spider), female (and male at the lower left?), dorsal
Once a very rare find at this place, so rare that I had to look it up to be sure but the typical zig-zag band and the lack of the quite distinct body-lobes of Argiope lobata gave it away. I don’t know if the wrapped spider at the lower left is indeed a male, I did not want to unwrap it. It also looks a bit too large for a male. The above picture has been slightly enhanced regarding colour saturation (not changes in hue!) and details, the two below the fold less so. (My camera is still a cheap digi-snapper without any ability to get the raw files).
Continue reading

When the dust hits the fan
Why is the CPU fan running at top speed almost constantly?
Well, it’s 30 degree Celsius, what do you expect?
And if all the people go to GibtLab now, just out of protest, is that a clone war?
With 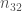
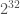
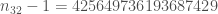

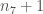
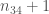
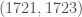
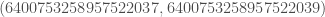
It is unknown if that information is of any use but as the saying goes: “You’ll never know!”.
You call it a revolution if the freedom-fighters won and a civil war if the
terrorists lost.
Eastbound, full rig, close-hauled, arse flung out leewards, with the luff scuppers three feet under water.
Solo sailor, wet, really wet
If you think that the sky is the limit you should refrain from working for NASA.
Anonymous government employee.
